
Comme beaucoup d’entre-nous, j’ai (eu) des boîtes en plastiques, des trieurs, des pochettes pour les fiches de paies, déclarations d’imposition, factures réglées, diplômes, bilans de santé et dossiers d’hospitalisation etc.
J’ai malheureusement vu dans mon entourage les désastres provoqués par des incendies ou cambriolages et la perte de certains documents. J’ai donc pris pour habitude il y a des années de scanner tous les documents papiers « importants » que je recevais et de les archiver dans des dossiers éponymes. Dossiers ensuite sauvegardés localement et sur le Cloud, après chiffrement.
Mais ça fait aussi quelques temps que je songe à optimiser tout ça, immédiatement suivi du fameux « Un jour » 🙂
Paperless, et maintenant Paperless-ng, rendent justement toute cette numérisation plus simple.
TL ; DR: ce truc est tout simplement top !
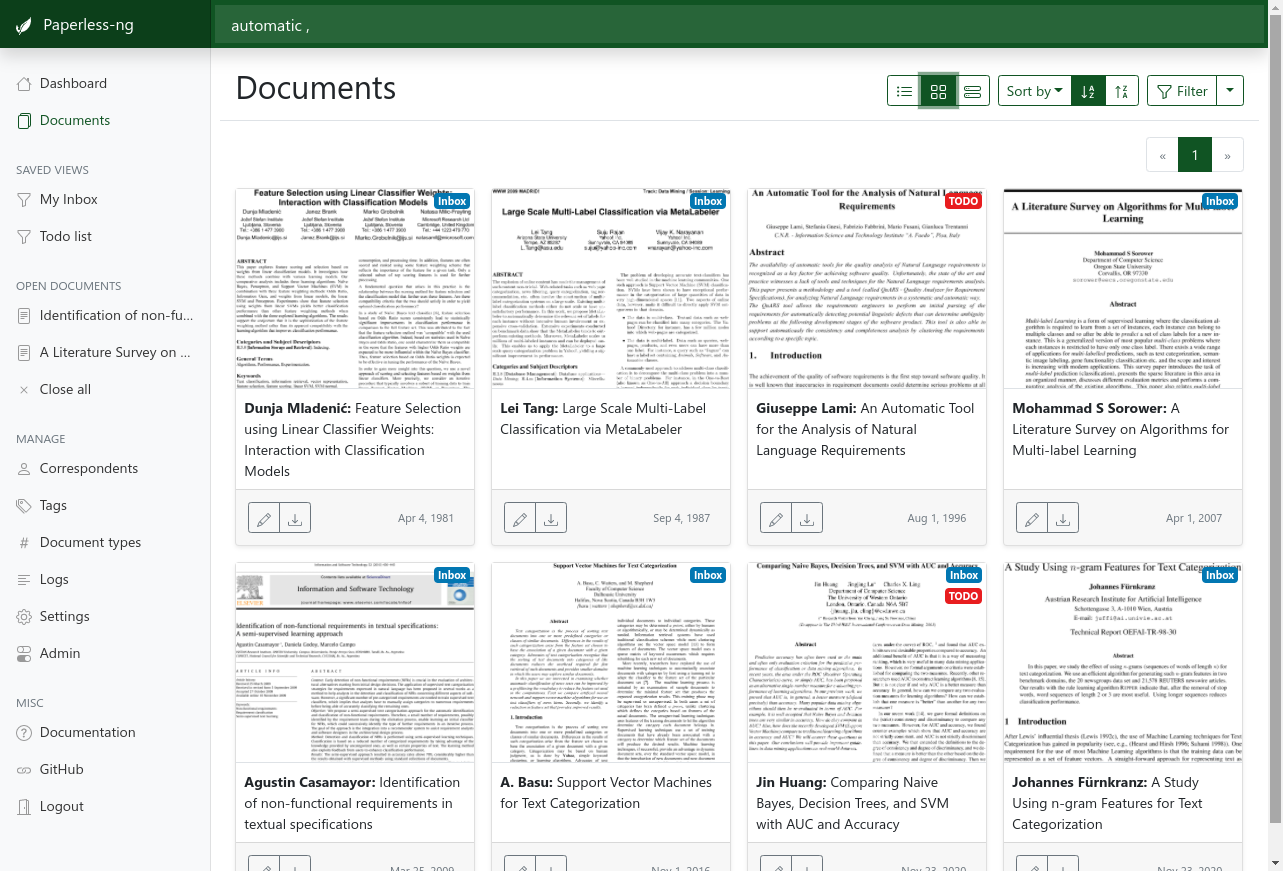
D’avantage de screens dans la documentation.
Le principe est simple : on l’alimente (FTP, upload, email, client mobile) avec des documents (images, PDF, MSOffice, LibreOffice, .txt, scans…) et il aide à les trier (OCR, tags…), les archiver et les rend accessible via mots clés/catégories/date/whatever, en format PDF notamment.
Bien évidemment ça suppose de pouvoir scanner des documents (Cap’tain Obvious!). Du coup on voit vite si on a l’équipement requis, à savoir un modèle précis (parce que testé) de scanner ou une application Android/iOS. Notez que pour Android il y a également (et je me sers de) PaperlessApp & PaperlessShare.
Il n’intègre pas de solution de chiffrement. La logique étant qu’on stocke en général nos documents personnels dans un endroit relativement sécurisé (si vous venez de Windows, ne vous posez pas trop de questions ^^’) et que chacun a sa solution de sauvegarde (3-2-1 de préférence, là on ne parle de films de vacances) qui inclut du chiffrement.
Pour simplifier l’installation ils proposent notamment plusieurs compose (Docker donc). Je privilégie la version « Tika & PostgreSQL« .
Apache Tika permet d’extraire les métadonnées des documents Office notamment et je pense que Postgre sera plus performant que SQLite dans ce contexte de traitement de gros volumes de données.
J’adapte les fichiers pour ma configuration
.env
COMPOSE_PROJECT_NAME=paperlessdocker-compose.env : clé secrète + TZ + français
USERMAP_UID=1000
USERMAP_GID=1000
PAPERLESS_SECRET_KEY=mgp5pwptQo7WIfVBU8BsHyMGXk1LVSN2uNcpX1I1wnNYHDS4kDHFrwRHR5XS3DBEA
PAPERLESS_TIME_ZONE=Europe/Paris
PAPERLESS_OCR_LANGUAGE=fraAu niveau des dossiers à monter :
/var/lib/postgresql/data = données SQL
/usr/src/paperless/data = données générales (config)
/usr/src/paperless/media = documents traités (archivés)
/usr/src/paperless/consume = dossier de réception des documents à traiter
Attention, pour pouvoir assimiler des fichiers *Office, il faut des versions précises de Gotenberg et Tika (j’ai testé en vain toutes les autres).
docker-compose.yml
version: "3.4"
services:
broker:
image: redis:6.0
container_name : paperlessredis
restart: always
db:
image: postgres:13
container_name : paperlesspostgres
restart: always
volumes:
- /home/aerya/docker/paperless/sql:/var/lib/postgresql/data
environment:
POSTGRES_DB: xxx
POSTGRES_USER: xxx
POSTGRES_PASSWORD: xxx
webserver:
image: jonaswinkler/paperless-ng:latest
container_name : paperless
restart: always
depends_on:
- db
- broker
- gotenberg
- tika
ports:
- 8024:8000
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8024"]
interval: 30s
timeout: 10s
retries: 5
volumes:
- /home/aerya/docker/paperless/data:/usr/src/paperless/data
- /Data/paperless/media:/usr/src/paperless/media
- /Data/paperless/consume:/usr/src/paperless/consume
env_file: docker-compose.env
environment:
PAPERLESS_REDIS: redis://broker:6379
PAPERLESS_DBHOST: db
PAPERLESS_TIKA_ENABLED: 1
PAPERLESS_TIKA_GOTENBERG_ENDPOINT: http://gotenberg:3000
PAPERLESS_TIKA_ENDPOINT: http://tika:9998
labels:
- com.centurylinklabs.watchtower.enable=true
gotenberg:
image: thecodingmachine/gotenberg:6
container_name : paperlessgotenberg
restart: always
environment:
DISABLE_GOOGLE_CHROME: 1
DEFAULT_WAIT_TIMEOUT: 30
tika:
image: apache/tika:1.27
container_name : paperlesstika
restart: alwaysEt me contente de suivre les instructions
[root@pve docker]$ mkdir paperless
[root@pve docker]$ cd paperless/
[root@pve paperless]$ nano .env
[root@pve paperless]$ nano docker-compose.env
[root@pve paperless]$ nano docker-compose.yml
[root@pve paperless]$ nano docker-compose.yml
[root@pve paperless]$ docker-compose pull
[...]
[root@pve paperless]$ docker-compose run --rm webserver createsuperuser
Creating paperlessredis ... done
Creating paperlessgotenberg ... done
Creating paperlesspostgres ... done
Creating paperlesstika ... done
Paperless-ng docker container starting...
Creating directory /tmp/paperless
Adjusting permissions of paperless files. This may take a while.
Waiting for PostgreSQL to start...
Apply database migrations...
Operations to perform:
Apply all migrations: admin, auth, authtoken, contenttypes, django_q, documents, paperless_mail, sessions
Running migrations:
Applying contenttypes.0001_initial... OK
Applying auth.0001_initial... OK
Applying admin.0001_initial... OK
[...]
Applying paperless_mail.0008_auto_20210516_0940... OK
Applying sessions.0001_initial... OK
Executing management command createsuperuser
Username (leave blank to use 'paperless'): aerya
Email address: [email protected]
Password:
Password (again):
Superuser created successfully.
[root@pve paperless]$ docker-compose up -d
paperlessredis is up-to-date
paperlesspostgres is up-to-date
paperlessgotenberg is up-to-date
paperlesstika is up-to-date
Creating paperless ... done
Bien entendu y’aura un reverse-proxy d’ajouté pour faire propre 🙂
Je vais pas détailler tout le fonctionnement, déjà parce que la doc le fera mieux que moi, ensuite parce que je le découvre aussi. Niveau documentation justement, voici des liens importants : les différentes solutions d’ajout de document, comprendre les termes (Correspondant, Tags etc), comprendre la recherche.
Je vais par exemple ajouter une facture depuis le navigateur
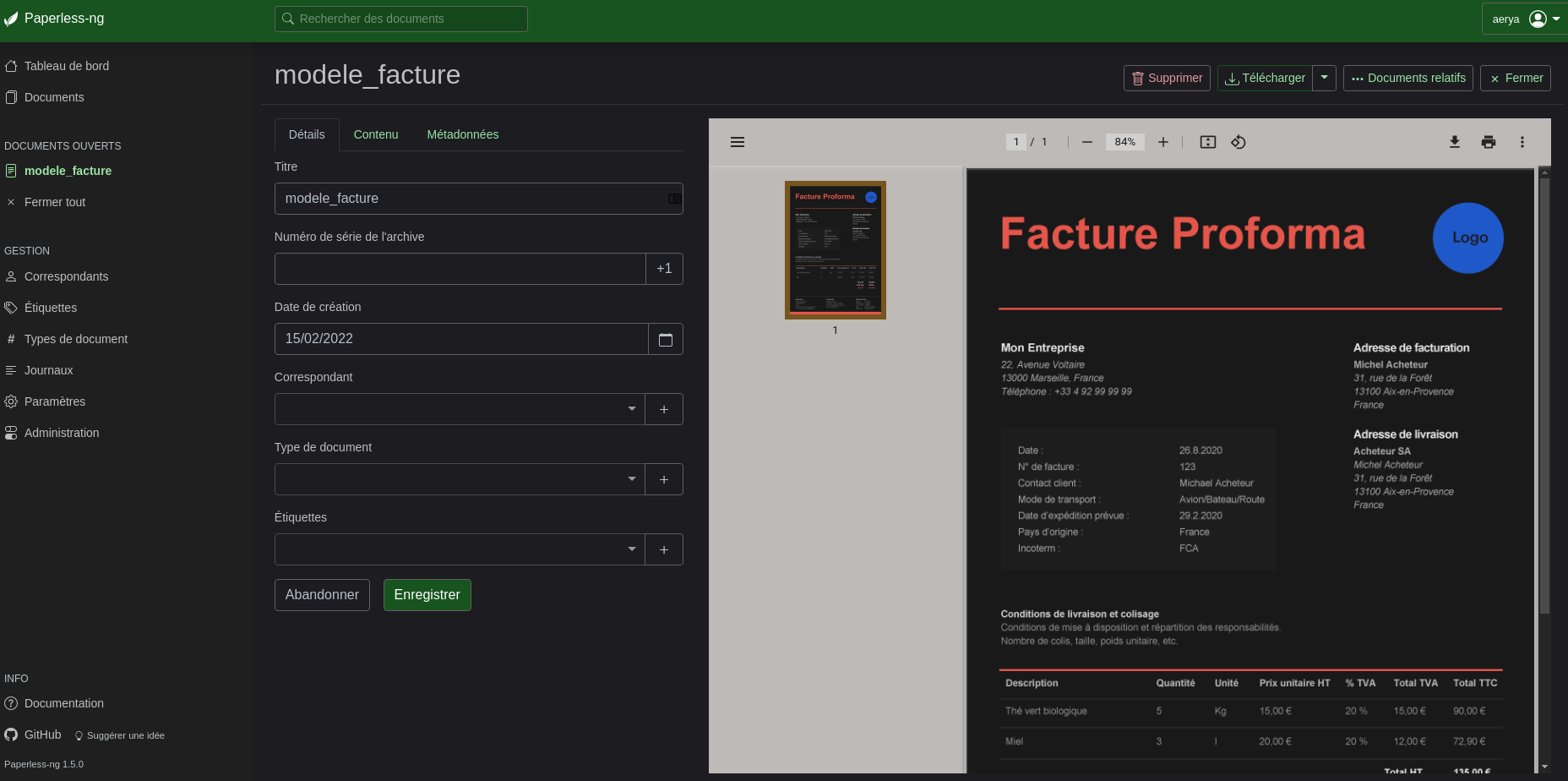
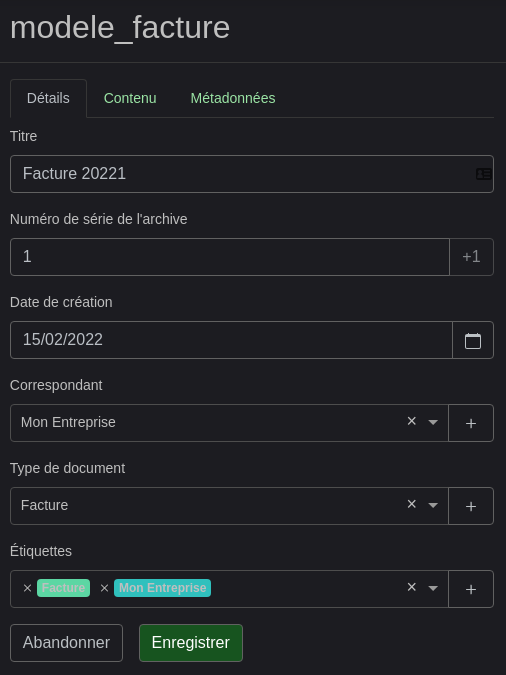
Sur ce 1er onglet on peut voir/modifier/ajouter/créer diverses informations liées au document. Je vais par exemple faire comme si c’était une facture émise par ma société pour le client M. ACHETEUR.
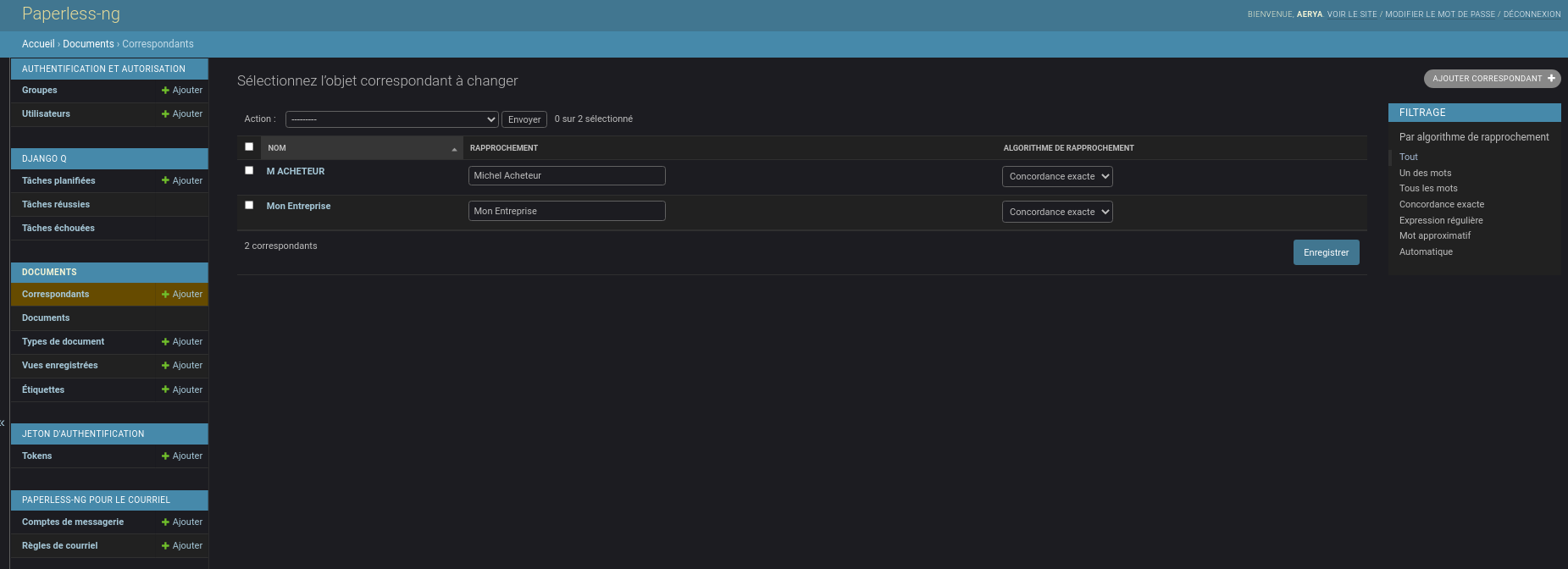
Paperless-ng « apprend » et gagne en autonomie. Quand j’ajoute mon client M. ACHETEUR comme Correspondant, j’indique à Paperless-ng comment repérer et attribuer ce correspondant au futurs ajouts de documents le concernant
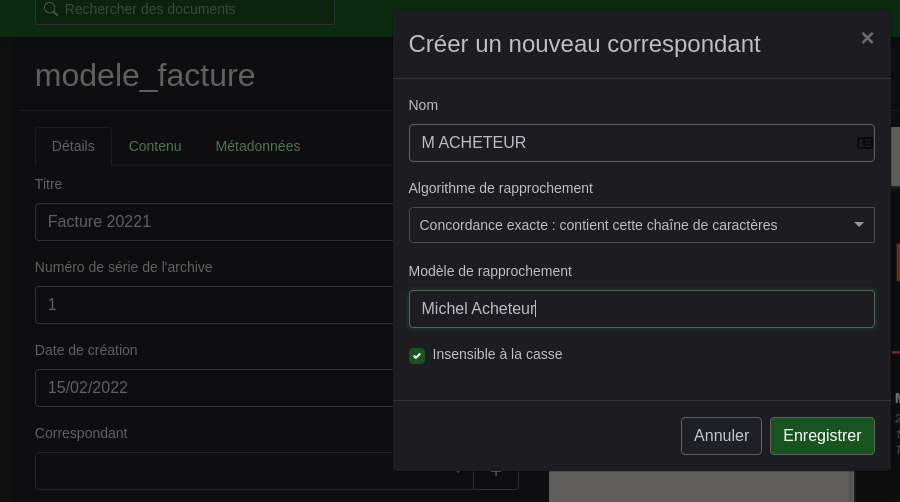
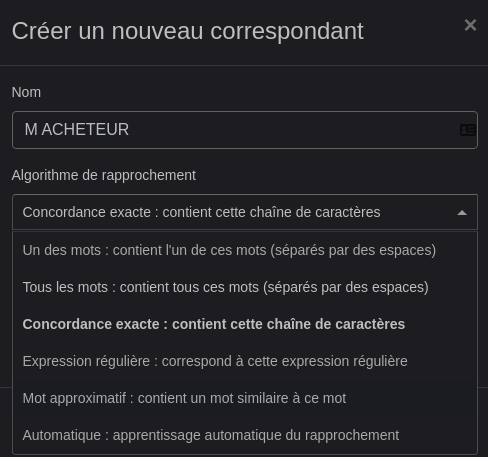
Tout comme j’ajoute également Mon Entreprise
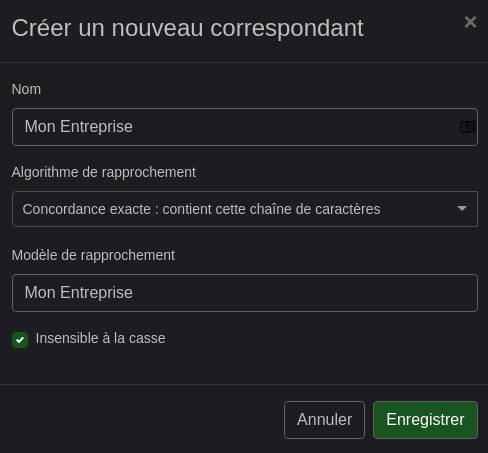
J’ai donc les 2 correspondants. Si j’avais une SARL je pourrais aussi ajouter le comptable par exemple.
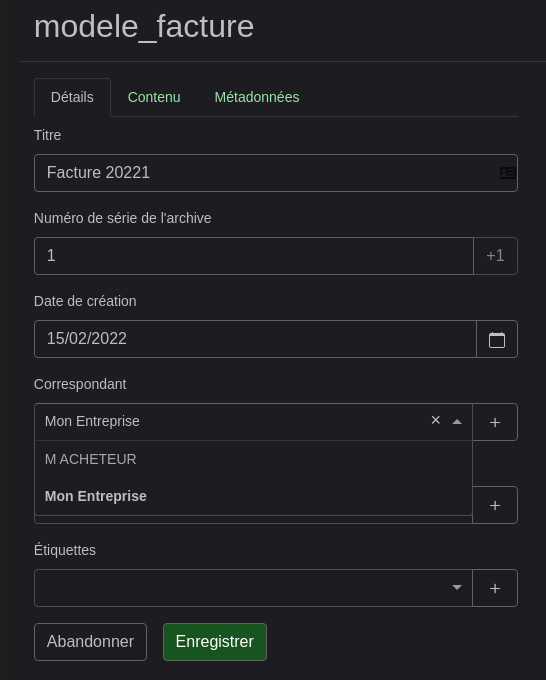
Même principe pour le Type de document
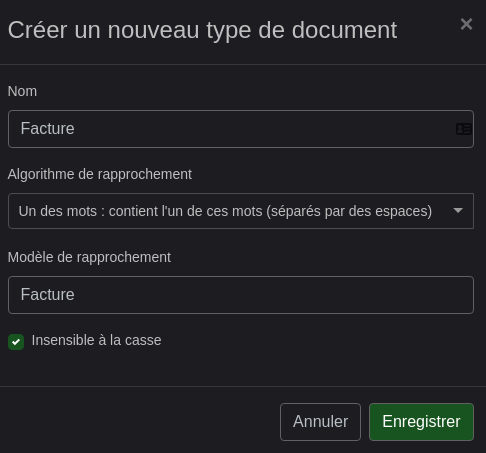
Et les étiquettes (tags)
On retrouve tout (ou on peut le créer dans) le panneau d’administration
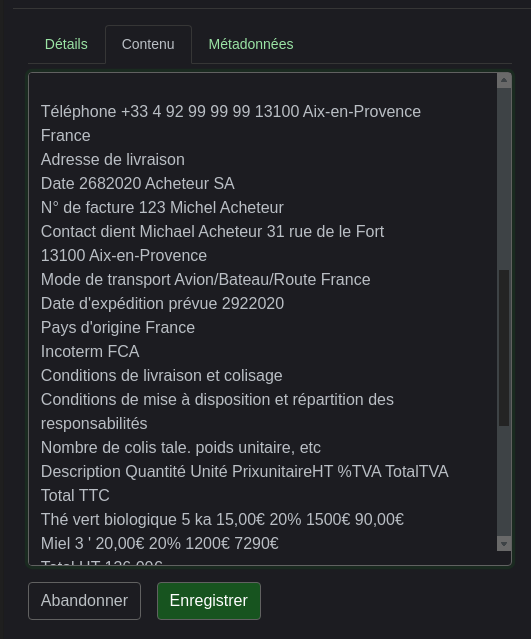
Le contenu est OCRisé et pourra aussi être recherché (enfin je crois)
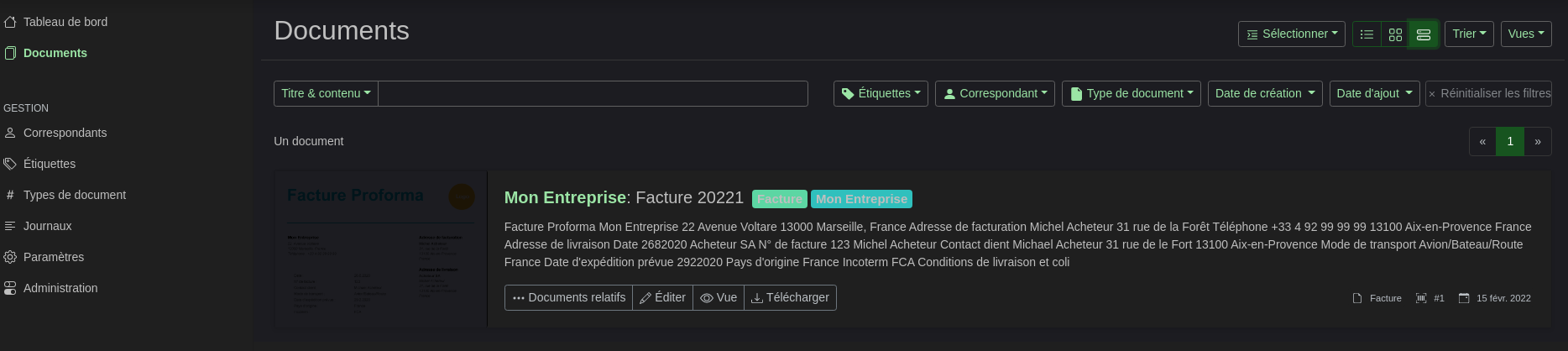
Et voilà, j’ai mon 1er document d’archivé 🙂
Faut pas se mentir, comme à chaque « 1ère fois » ça va me prendre du temps d’ajouter tous nos documents et de créer les tags et autres afférents. Mais ensuite ajouter les documents au fil de l’eau, souvent de manière automatique (email + tags/correspondant auto) sera bien moins chronophage !
Dans leurs docker-compose ils ajoutent le dossier /export dans les montages. Celui-ci sert à exporter tout le contenu de Paperless-ng (données, configs, docs) en vue d’une sauvegarde ou d’une migration. Utilisant Docker ce n’est pas utile. Mon dossier /home/aerya/docker est déjà sous dans un cycle de backup et il ne manque que /Data/paperless, que j’ajoute.
J’ai testé avec des fichiers Excel et Classeur, ils sont bien reconnus et transformés en PDF.