
Mais pourquoi utiliser Jellyfin pour lire depuis des addons Stremio alors que Wuplay et Nuvio sont beaux, performants et en pleine évolution ?
Parce que :
– Je suis curieux et geek,
– J’aime Jellyfin et ses plugins,
– J’anticipe un futur setup hybride que d’autres clients d’indexation et lecture ne pourrons pas permettre (même si j’ai créé un addon Seerr pour Stremio pour faire des demandes de contenus)
– Parce qu’à l’époque où j’ai testé Gelato y’avait pas encore Nuvio ni Wuplay si on ne veut que du streaming,
– Parce qu’avoir son serveur Jellyfin permet de diffuser du contenu en streaming depuis AIOstreams (ce tutoriel), en streaming depuis BitTorrent (Decypharr) ou Usenet (NZBdav) ou en local (BitTorrent, Usenet, Emule via Amarr).

Testé il y a environ 1 an, j’avais pas accroché à Gelato. Sans doute parce que mes catalogues Stremio n’étaient pas optimisés… (oui je sais, vous me l’avez assez répété).
Gelato permet d’intégrer ses catalogues Stremio (uniquement via l’addon AIOStreams) dans Jellyfin et, évidemment, de lire les flux comme le ferait tout client compatible avec les addons Stremio : en streaming depuis les débrideurs.
Selon le nombre de catalogues qu’on lui ajoute et le nombre de contenus qu’on lui fait indexer par catalogue, ça peut prendre des heures lors du 1er import dans Jellyfin.
J’héberge tous mes addons Stremio, y compris le futur StreamFusion Reborn (beta fermée malgré une version déjà remodelée et publique) qui apporte de très nombreuses options de cache et de partage de hashes.
J’utilise également l’excellent Baguettio de stremiofr.me dont le code n’est pas publié et donc sans pouvoir l’héberger.
Je teste avec 22 catalogues :
- REDACTED-Films
- REDACTED-Documentaires
- REDACTED-Séries
- REDACTED-Séries d’animation
- Les nouveautés (Séries TV)
- Les nouveautés (Films)
- Top pirated and popular movies
- Seerr Movies
- Seerr Series
- Netflix (Movies)
- Netflix (Series)
- HBO Max (Movies)
- HBO Max (Series)
- Apple TV+ (Movies)
- Apple TV+ (Series)
- Prime Video (Movies)
- Prime Video (Series)
- Stremio RSS Catalog – Films
- Stremio RSS Catalog – Documentaires
- Stremio RSS Catalog – Séries
- Netflix – Top 10 France
- Netflix – Top 10 France
Pour ce tutoriel je prends une base fresh install de Jellyfin 10.11.8, j’ai mon reverse proxy https://jelly.domain.tld et j’ai créé des bibliothèques dédiées à Gelato dans mon stockage de fichiers : /mnt/torrent/gelatofilms et /gelatoseries
J’anticipe une évolution vers un setup hybride :
– Streaming via AIOStreams,
– Streaming via Usenet/BitTorrent (d’où mon volume /mnt:/mnt),
– Lecture depuis des sources locales (d’où l’ajout de /dev/dri).
services:
jellyfin:
image: lscr.io/linuxserver/jellyfin:latest
container_name: jellyfin
restart: always
environment:
PUID: 0
PGID: 0
TZ: Europe/Paris
JELLYFIN_PublishedServerUrl: https://jelly.domain.tld
ports:
- 8096:8096
- 8920:8920
- 7359:7359/udp
- 1932:1900/udp
volumes:
- /mnt/databases/jellyfin:/config
- /mnt:/mnt
- /mnt/torrent:/data/
devices:
- /dev/dri:/dev/driUne fois installé, le compte utilisateur créé, on peut installer Gelato via le menu Extensions, d’abord en ajoutant son dépôt comme indiqué dans la doc.
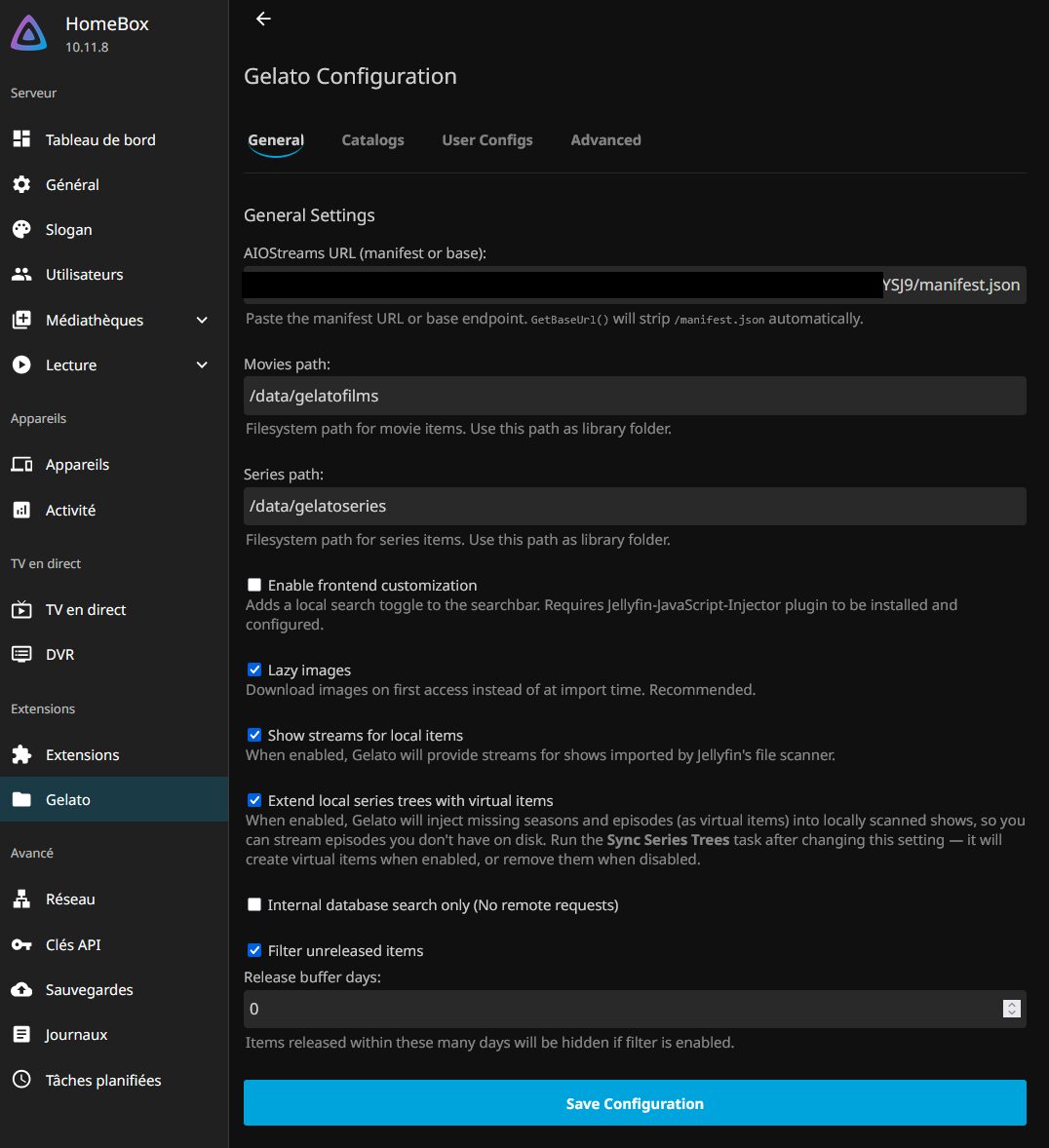
Et je passe à sa configuration en ajoutant l’URL du manifeste de mon AIOStreams. Je mets les chemins vers mes bibliothèques dédiées.
Je n’active pas Frontend Customization qui ne peut fonctionner qu’avec le client Web mais pas les clients AndroidTV etc.
J’active la récupération des images lors de l’import des catalogues.
Comme j’anticipe un setup hybride, j’active aussi Show streams for local items qui permet d’exposer les fichiers déjà présents localement comme sources de lecture, en complément des streams AIOStreams.
Même principe avec Extend local series trees virtual items qui permet à Gelato de chercher/afficher des saisons et/ou épisodes manquants localement. Plutôt complémentaire de l’option précédente pour moi.
Je n’active pas Internal database search only qui limiterait la recherche de Jellyfin à sa base de données locale seulement.
Et j’active enfin Filter unreleased items (avec un buffer à 0) afin que Gelato ne propose pas dans Jellyfin de contenus considérés comme non sortis, en se basant principalement sur les dates de sortie digitales issues des métadonnées TMDB/IMDb (lorsqu’elles sont disponibles…).
ATTENTION, les chemins indiqués dans le plugin Gelato doivent être les mêmes que ceux utilisés pour ajouter des bibliothèques. Donc dans mon cas soit /data/gelatofilms soit /mnt/torrent/gelatofilms.
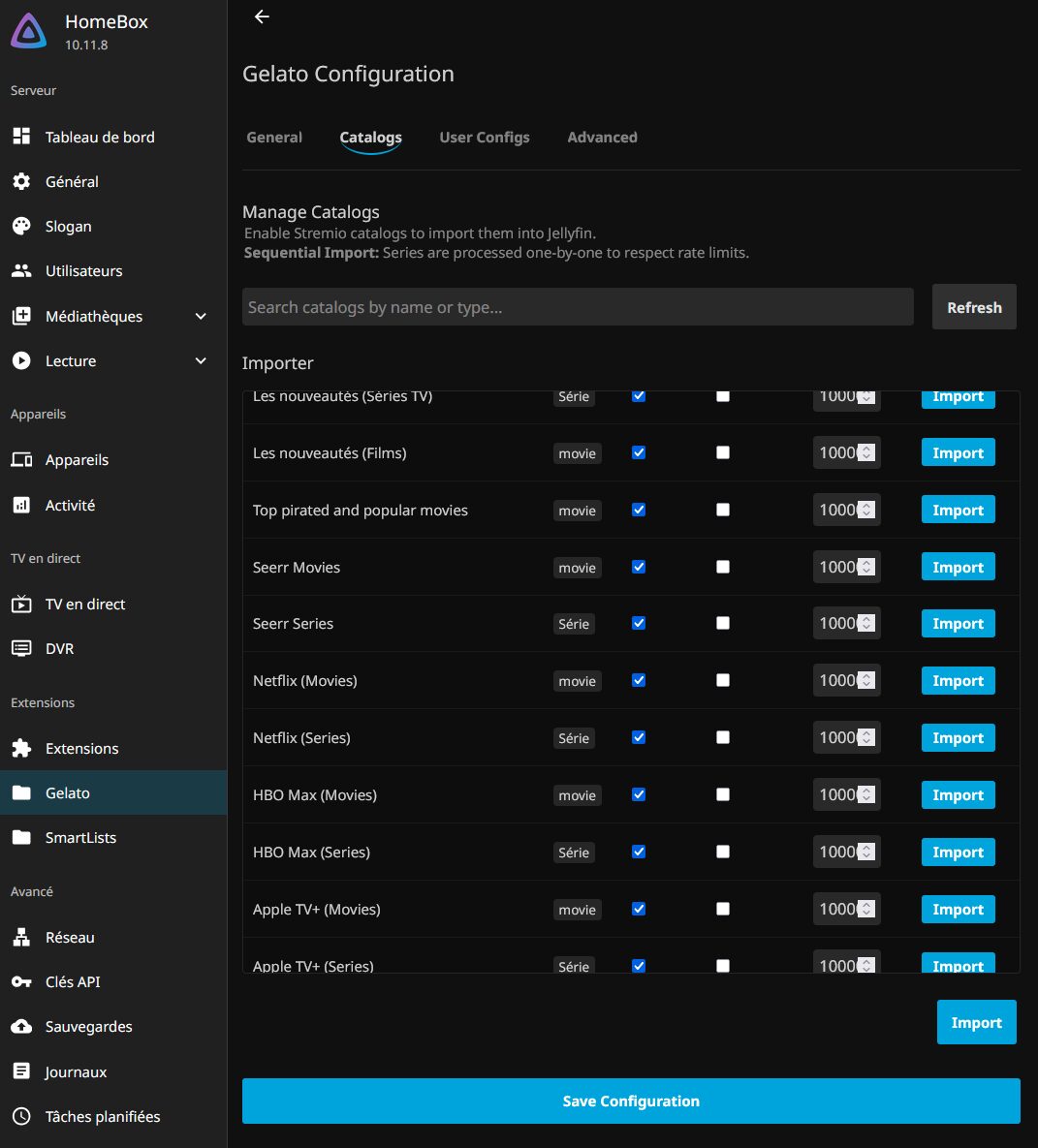
Une fois cette configuration sauvegardée, on peut parcourir nos catalogues et sélectionner ceux qu’on veut utiliser comme sources de médias pour Jellyfin (voire pour créer des collections).
Comme j’ai des gros sabots, je modifie la règle de base de 100 médias/catalogue en import pour passer ça à 10.000.
Évidemment, ça n’est utile que si vous avez des catalogues aussi importants (voire plus). C’est mon cas avec des catalogues privés dont ceux qu’on peut créer à partir de flux RSS avec mon addon useFlow-FR (que je suis en train de refaire complètement). Je l’ai pas encore remis en route suite à ma réinstallation de serveur mais pour ce test j’ai normalement déjà de quoi faire.
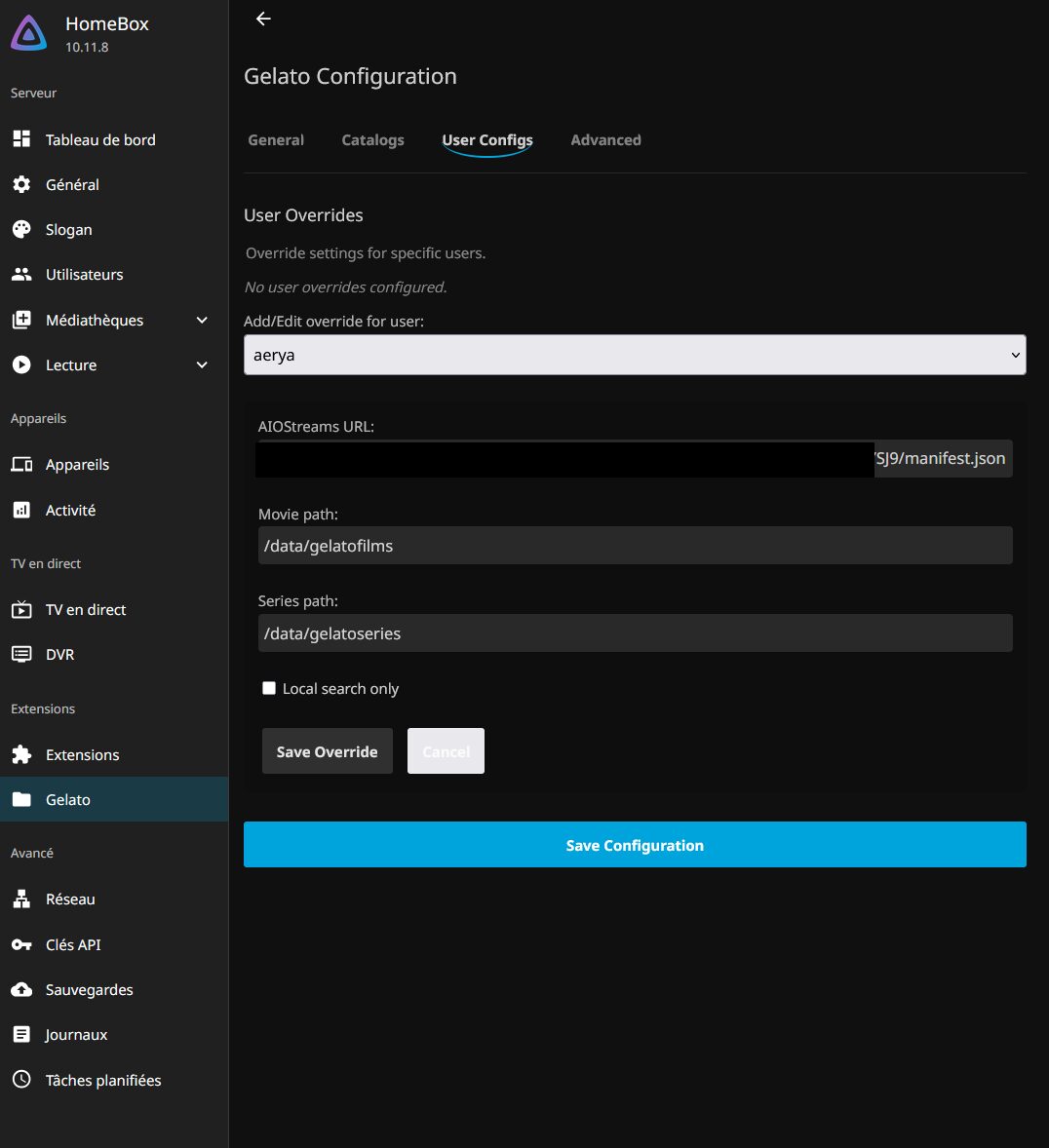
Pour ceux qui utilisent Jellyfin à plusieurs, on peut paramétrer le manifeste AIOStreams et la recherche par user.
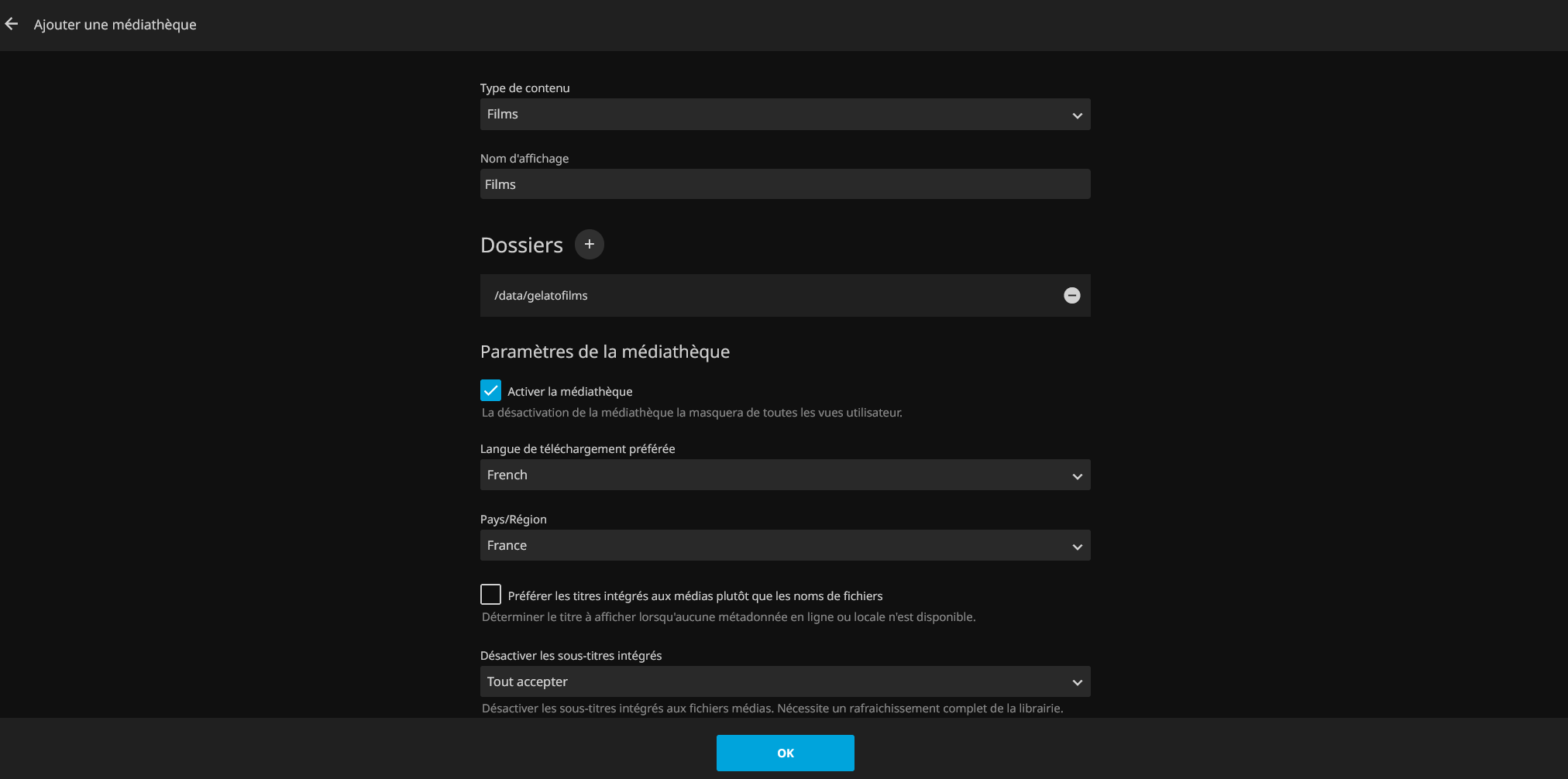
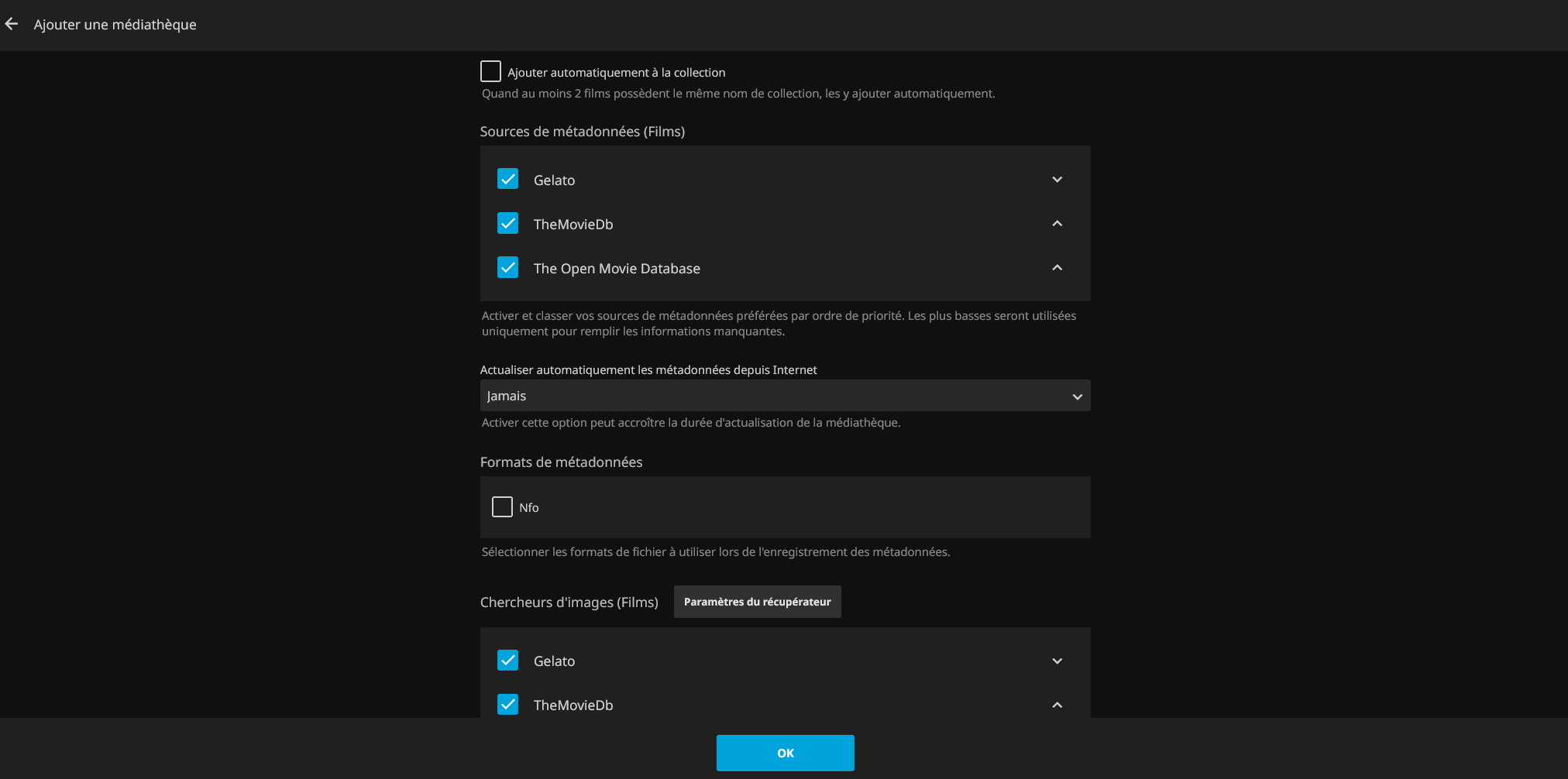
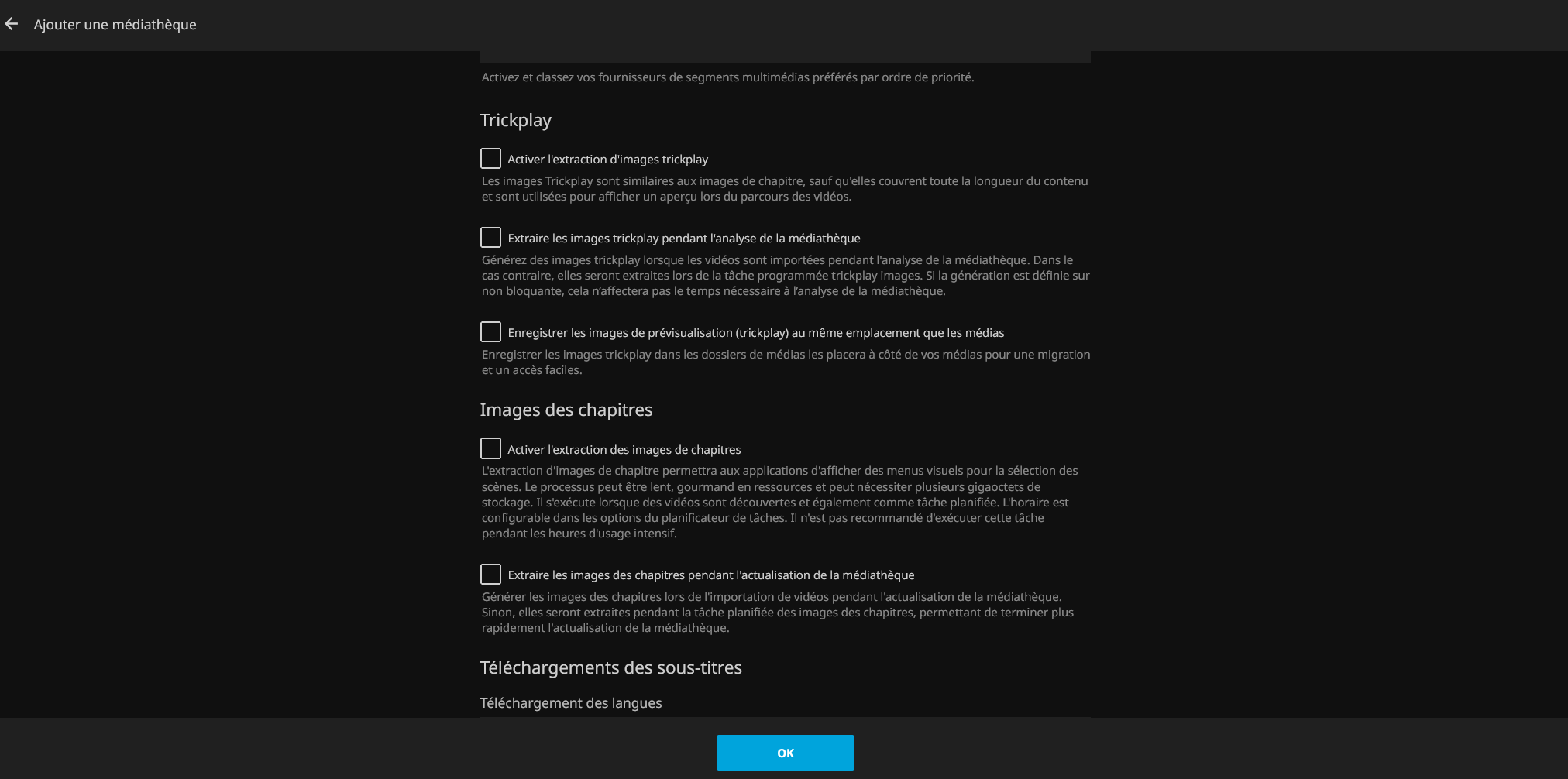
Il faut ensuite créer les médiathèques de films et de séries. Comme on est sur du streaming, il ne faut pas activer le trickplay et la création des images etc, ça ne concerne que des médias locaux. Je n’active pas la recherche des sous-titres, je ne consomme que du FRENCH/MULTi ou du VOSTFR.
Il ne reste qu’à importer les catalogues. Comptez de quelques minutes à plusieurs heures selon leurs nombre et taille.
Plutôt que d’attendre qu’il se déclenche automatiquement, je force son démarrage.
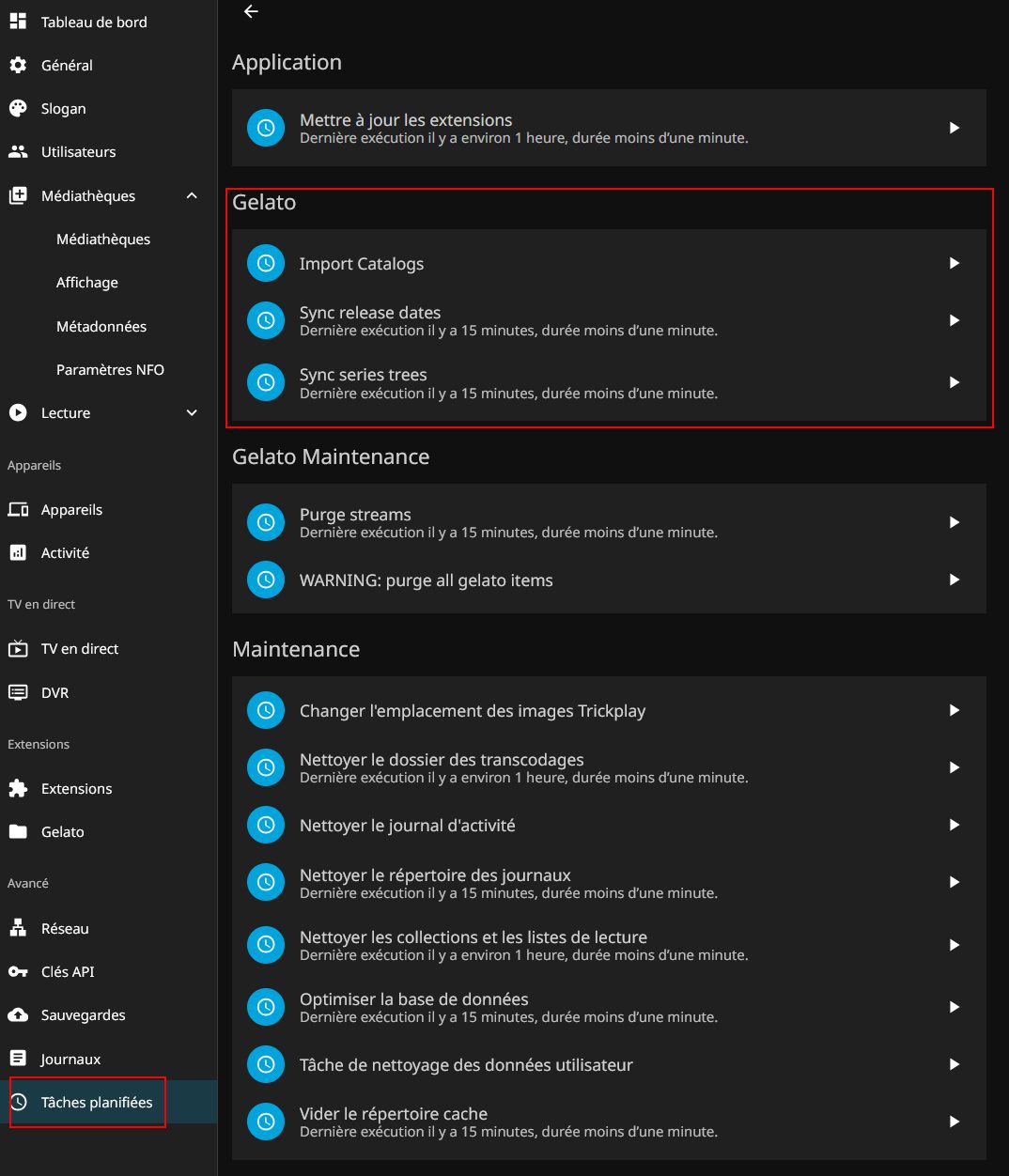
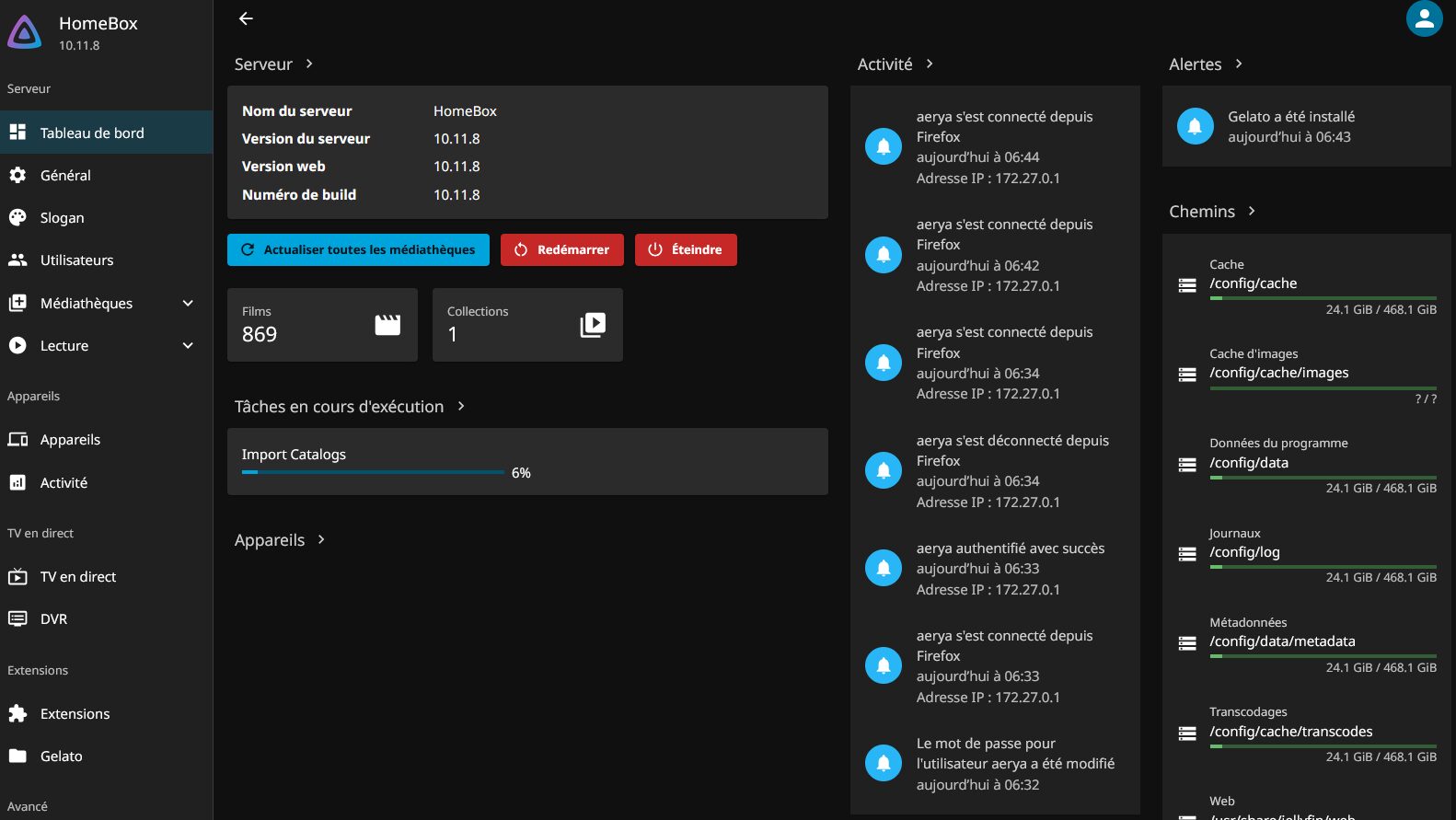
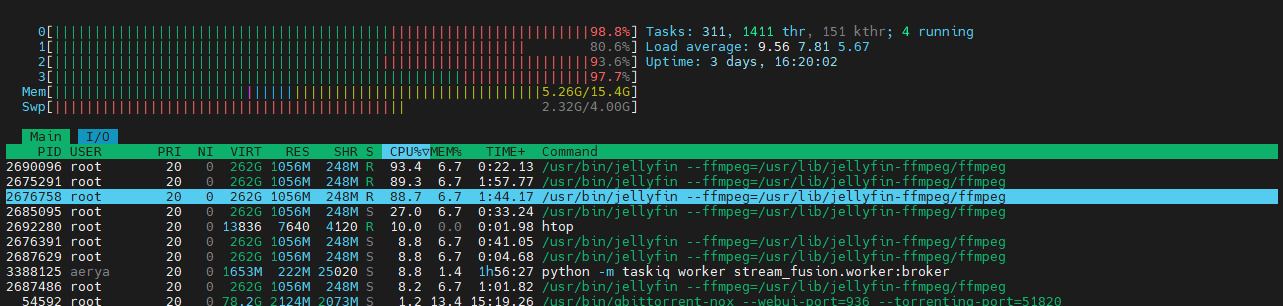
ça bosse… Mon LincStation N1 est bien vaillant quand même… Avec son N5105 il prend cher au 1er l’import ! Heureusement ensuite pour l’utilisation et la lecture c’est peanuts.
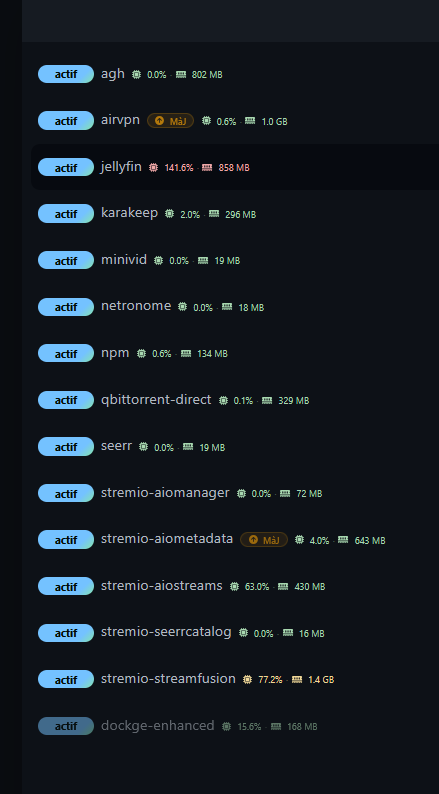
Bémol : Gelato ne sait gérer que 2 bibliothèques : films et séries. Pour les documentaires, spectacles etc, il faut soit forker Gelato et ajouter la création de bibliothèques (mapping de catalogues vers des bibliothèques Jellyfin) soit utiliser un plugin de création de collections comme Smart Lists par exemple pour filtrer les contenus par tags.
Le lendemain, j’ai pas tué mon LincStation \o/ et l’import est terminé (16h à ce que je vois dans les logs)
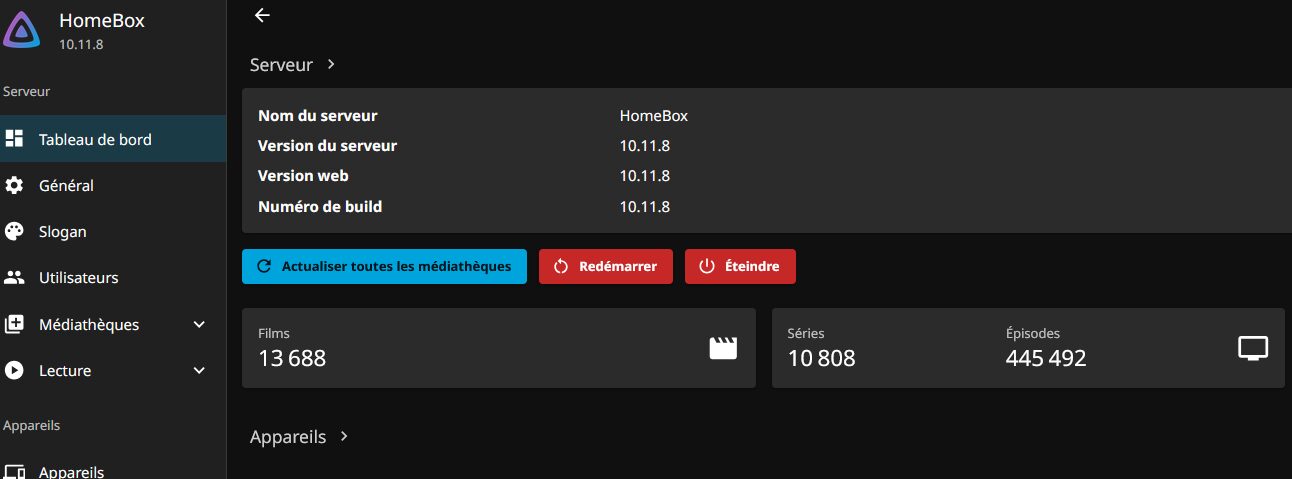
Et on peut donc choisir le flux lors de la lecture, selon la configuration d’AIOStreams. Pour ma part je filtre FRENCH/MULTI, 720 (HD)/1080 (FHD)/2160p (UHD) et 2 releases par résolution au global. Je suis pas du tout fan des listes de 47 releases…
AIOStreams gère également l’apparence des releases.
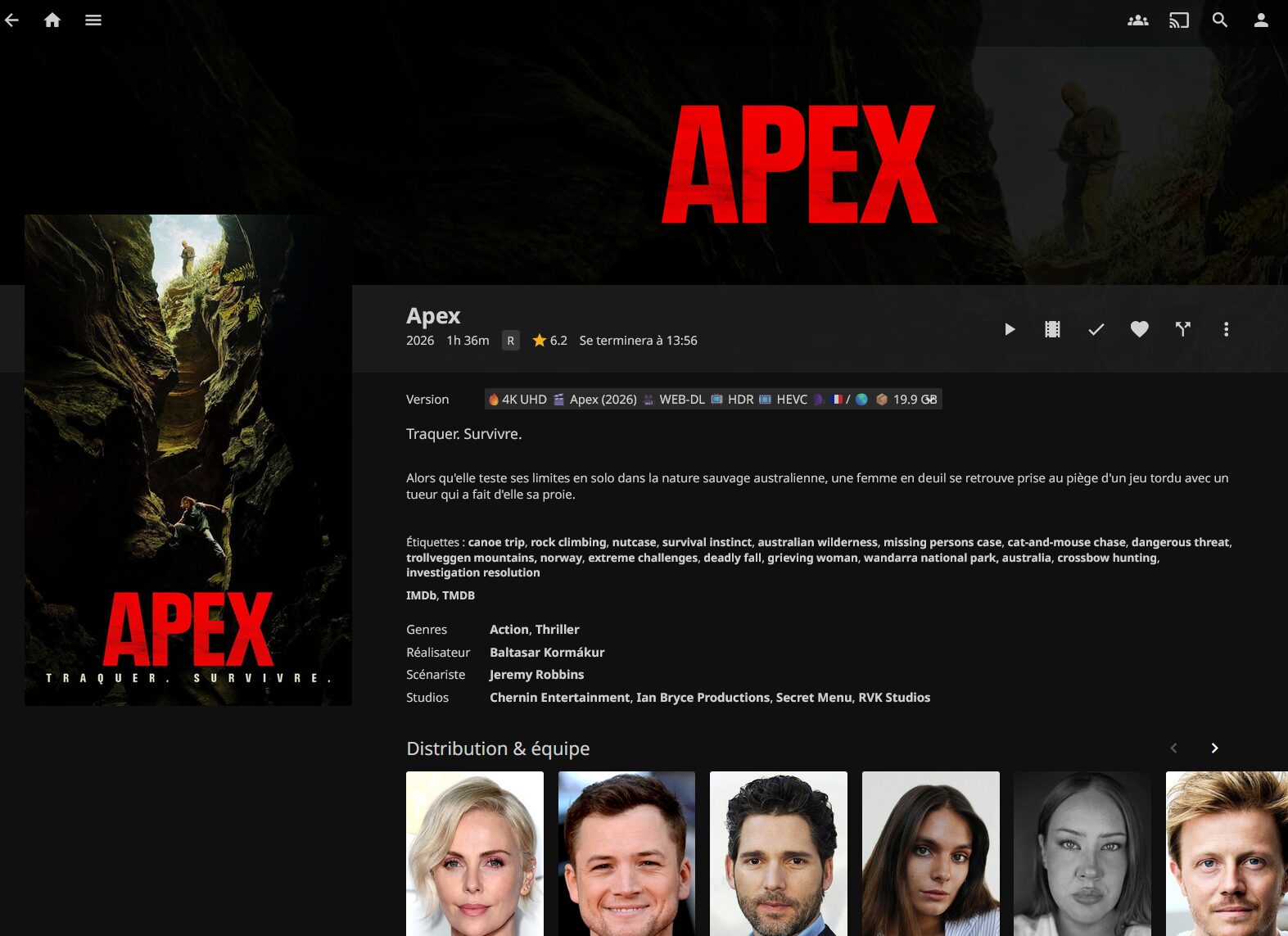
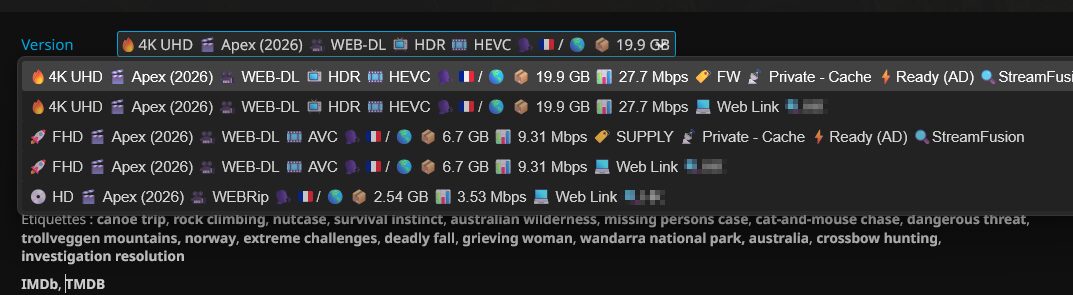
Pour ceux qui peinent à écrire sur la config via Docker, utiliser l’ip:port et non le nom de domaine pour Gelato.
Yo,
Tu peux également ajouter un petit script via API Jellyfin pour refresh les metadatas.
Pcq sinon il n’y a pas de refresh des épisodes ajoutés en « next aired »
Il est sur le discord de gelato,
Sinon les voici :
config.ini :
[JELLYFIN]
# Your Jellyfin server URL (include http/https and port)
url = http://192.168.1.xxx:8096
# The API key you generated in the Jellyfin Dashboard
api_key = xxxxxxxxxxc441939f916421c5723292
# A newline-separated list of TV Show libraries to scan
libraries =
Show
Anime
[SETTINGS]
# How many minutes the script should wait between refresh cycles
interval_min = 1200
# Refreshes episodes that aired within this many days in the past
age_days = 10
# Refreshes episodes airing in this many days in the future (-1 for all future)
future_days = 10
# Set to True to replace images along with metadata, False to keep existing images
replace_images = True
# Mode: « missing » (only search for missing metadata) or « all » (replace everything)
mode = all
refresh_recent_episode_meta.py :
#!/usr/bin/env python3
import configparser
import logging
import sys
import time
from dataclasses import dataclass
from datetime import datetime, timedelta, timezone
from logging.handlers import RotatingFileHandler
from pathlib import Path
from typing import Any, Dict, List
import requests
logger = logging.getLogger(__name__)
@dataclass
class AppConfig:
url: str
api_key: str
libraries: List[str]
interval_min: int
age_days: int
future_days: int
replace_images: bool
mode: str
def parse_config(config_path: Path) -> AppConfig:
« » »Parses and validates the configuration file. » » »
if not config_path.exists():
logger.error(f »Configuration file not found at {config_path} »)
sys.exit(1)
parser = configparser.ConfigParser(inline_comment_prefixes=(« # », « ; »))
parser.read(config_path)
try:
sec_jellyfin = « JELLYFIN »
url = parser.get(sec_jellyfin, « url »).strip().rstrip(« / »)
api_key = parser.get(sec_jellyfin, « api_key »).strip()
# Parse multiline libraries
raw_libs = parser.get(sec_jellyfin, « libraries »)
libraries = [
lib.strip() for lib in raw_libs.split(« \n ») if lib.strip()
]
if not url or not api_key:
err_msg = « Jellyfin URL and API key must not be empty. »
logger.error(err_msg)
raise ValueError(err_msg)
if not libraries:
err_msg = « At least one library must be specified. »
logger.error(err_msg)
raise ValueError(err_msg)
sec_settings = « SETTINGS »
interval_min = parser.getint(sec_settings, « interval_min »)
age_days = parser.getint(sec_settings, « age_days »)
future_days = parser.getint(sec_settings, « future_days »)
replace_images = parser.getboolean(sec_settings, « replace_images »)
mode = parser.get(sec_settings, « mode »).strip().lower()
if mode not in [« missing », « all »]:
err_msg = f »Invalid mode ‘{mode}’. Must be ‘missing’ or ‘all’. »
logger.error(err_msg)
raise ValueError(err_msg)
if interval_min <= 0:
err_msg = « Interval must be a positive integer. »
logger.error(err_msg)
raise ValueError(err_msg)
if age_days < 0:
err_msg = « Age cannot be negative. »
logger.error(err_msg)
raise ValueError(err_msg)
if future_days < -1:
err_msg = « Future days cannot be less than -1. »
logger.error(err_msg)
raise ValueError(err_msg)
return AppConfig(
url=url,
api_key=api_key,
libraries=libraries,
interval_min=interval_min,
age_days=age_days,
future_days=future_days,
replace_images=replace_images,
mode=mode,
)
except configparser.Error as e:
logger.error(f »Failed to parse config file: {e} »)
sys.exit(1)
except ValueError as e:
logger.error(f »Configuration error: {e} »)
sys.exit(1)
def get_session(api_key: str) -> requests.Session:
« » »Initializes and returns an authenticated requests session. » » »
session = requests.Session()
session.headers.update(
{« X-Emby-Token »: api_key, « Content-Type »: « application/json »}
)
return session
def get_library_ids(
session: requests.Session, config: AppConfig
) -> Dict[str, str]:
« » »Fetches virtual folders (libraries) and maps configured names
to their IDs. » » »
logger.info(« Fetching library IDs from Jellyfin… »)
try:
r = session.get(f »{config.url}/Library/VirtualFolders »)
r.raise_for_status()
folders = r.json()
except Exception as e:
logger.error(f »Failed to fetch libraries: {e} »)
return {}
lib_ids = {
folder.get(« Name »): folder.get(« ItemId »)
for folder in folders
if folder.get(« Name ») in config.libraries
and folder.get(« ItemId »)
and folder.get(« CollectionType ») == « tvshows »
}
# Check for missing libraries
for lib in config.libraries:
if lib not in lib_ids:
logger.warning(
f »Library ‘{lib}’ was specified in config but not found on »
« the server, or is not a TV Shows library. »
)
return lib_ids
def fetch_items(
session: requests.Session,
config: AppConfig,
parent_id: str,
item_type: str,
) -> List[Dict[str, Any]]:
« » »Fetches items of a specific type from a parent ID, applying
relevant filters. » » »
params = {
« IncludeItemTypes »: item_type,
« Recursive »: « false »,
« ParentId »: parent_id,
}
if item_type == « Series »:
params[« SeriesStatus »] = « Continuing »
# uncomment the following line if your Shows library contains multiple
# base folders containing series so that it searches them recursively
# params[« Recursive »] = « true »
elif item_type == « Season »:
current_year = datetime.now(timezone.utc).year
params[« Years »] = f »{current_year},{current_year – 1} »
elif item_type == « Episode »:
cutoff_date = datetime.now(timezone.utc) – timedelta(
days=config.age_days
)
params[« MinPremiereDate »] = cutoff_date.isoformat()
if config.future_days != -1:
max_date = datetime.now(timezone.utc) + timedelta(
days=config.future_days
)
params[« MaxPremiereDate »] = max_date.isoformat()
r = session.get(f »{config.url}/Items », params=params)
r.raise_for_status()
return r.json().get(« Items », [])
def refresh_item(
session: requests.Session, config: AppConfig, item_id: str, item_name: str
) -> None:
« » »Triggers a metadata refresh on a specific item ID. » » »
metadata_mode = « FullRefresh » if config.mode == « all » else « Default »
image_mode = « FullRefresh » if config.replace_images else « Default »
replace_metadata_str = « true » if config.mode == « all » else « false »
replace_images_str = « true » if config.replace_images else « false »
params = {
« Recursive »: « false »,
« MetadataRefreshMode »: metadata_mode,
« ImageRefreshMode »: image_mode,
« ReplaceAllMetadata »: replace_metadata_str,
« ReplaceAllImages »: replace_images_str,
}
try:
r = session.post(
f »{config.url}/Items/{item_id}/Refresh », params=params
)
r.raise_for_status()
logger.info(f » Refreshed metadata for episode: ‘{item_name}' »)
except Exception as e:
logger.error(
f » Failed to refresh ‘{item_name}’ (ID: {item_id}): {e} »
)
def process_series(
session: requests.Session,
config: AppConfig,
series: Dict[str, Any],
) -> int:
« » »Processes a single series, fetching episodes and refreshing them. » » »
series_name = series.get(« Name », « Unknown Series »)
series_id = series.get(« Id »)
if not series_id:
return 0
all_recent_episodes = []
try:
seasons = fetch_items(session, config, series_id, « Season »)
except Exception as e:
logger.error(f »Failed to fetch seasons for series ID {series_id}: {e} »)
return 0
for season in seasons:
season_id = season.get(« Id »)
if season_id:
try:
episodes = fetch_items(session, config, season_id, « Episode »)
all_recent_episodes.extend(episodes)
except Exception as e:
logger.error(
f »Failed to fetch episodes for season ID {season_id}: {e} »
)
continue
refreshed_count = 0
if all_recent_episodes:
logger.info(
f »Found {len(all_recent_episodes)} recent episode(s) in »
f »‘{series_name}’. Refreshing… »
)
for ep in all_recent_episodes:
ep_name = ep.get(« Name », « Unknown Episode »)
ep_id = ep.get(« Id »)
if ep_id:
refresh_item(session, config, ep_id, ep_name)
refreshed_count += 1
return refreshed_count
def process_library(
session: requests.Session,
config: AppConfig,
lib_name: str,
lib_id: str,
) -> int:
« » »Processes a single library, searching for continuing series. » » »
logger.info(f »Scanning library ‘{lib_name}’ for continuing series… »)
try:
continuing_series = fetch_items(session, config, lib_id, « Series »)
except Exception as e:
logger.error(f »Failed to fetch series for library ID {lib_id}: {e} »)
return 0
if not continuing_series:
logger.info(f »No continuing series found in ‘{lib_name}’. »)
return 0
logger.info(
f »Found {len(continuing_series)} continuing series in ‘{lib_name}’. »
f »Scanning for episodes aired in the last {config.age_days} days… »
)
refreshed_count = 0
for series in continuing_series:
refreshed_count += process_series(session, config, series)
return refreshed_count
def run_refresh_cycle(config: AppConfig, session: requests.Session) -> None:
« » »Runs a single iteration of the refresh cycle. » » »
logger.info(« Starting metadata refresh cycle… »)
lib_ids = get_library_ids(session, config)
if not lib_ids:
logger.warning(« No valid libraries found to process. »)
return
total_refreshed = 0
for lib_name, lib_id in lib_ids.items():
total_refreshed += process_library(session, config, lib_name, lib_id)
logger.info(
f »Refresh cycle complete. Total episodes refreshed: {total_refreshed} »
)
def main() -> None:
log_dir = Path(__file__).parent / « logs »
log_dir.mkdir(exist_ok=True)
logging.basicConfig(
level=logging.INFO,
format= »%(asctime)s [%(levelname)s] %(message)s »,
datefmt= »%Y-%m-%d %H:%M:%S »,
handlers=[
logging.StreamHandler(sys.stdout),
RotatingFileHandler(
log_dir / « daemon.log »,
maxBytes=5 * 1024 * 1024, # 5 MB limit
backupCount=3, # Keep up to 3 old log files
),
],
)
config_path = Path(__file__).parent / « config.ini »
config = parse_config(config_path)
session = get_session(config.api_key)
logger.info(
f »Initialized daemon. Running every {config.interval_min} minutes. »
)
future_str = « all » if config.future_days == -1 else str(config.future_days)
logger.info(
f »Configured to check episodes from the last {config.age_days} »
f »day(s) and {future_str} future day(s). »
)
while True:
try:
run_refresh_cycle(config, session)
except Exception as e:
logger.error(
f »Unexpected error during refresh cycle: {e} », exc_info=True
)
logger.info(f »Sleeping for {config.interval_min} minutes…\n »)
time.sleep(config.interval_min * 60)
if __name__ == « __main__ »:
main()
services:
jellyfin-refresher:
command: >-
sh -c « pip install –no-cache-dir requests && python -u
refresh_recent_episode_meta.py »
container_name: gelato-metadata-refresher
image: python:3.14-slim
restart: unless-stopped
volumes:
– >-
/mnt/NVME_512Go/Apps/gelato-metadata-refresh/refresh_recent_episode_meta.py:/app/refresh_recent_episode_meta.py:ro
– >-
/mnt/NVME_512Go/Apps/gelato-metadata-refresh/config.ini:/app/config.ini:ro
– /mnt/NVME_512Go/Apps/gelato-metadata-refresh/logs:/app/logs
working_dir: /app
version: ‘3.8’
Bisous l’ami
Merci de l’info 🙂
Tiens, tant que j’y pense !
le parfait compagnon pour Gelato c’est Cavea (il est eol mais encore fonctionnel)
il « probe » le fichier avec ffmpeg pour déterminer les pistes audios et subs avant lecture, dès sa sélection dans la liste des sources.
2 avantages:
-tu peux choisir les pistes avant lancement (pas sur l’app Android TV par contre)
-au lancement d’une vidéo, il n’y a jamais de loupés sur les pistes disponibles (ça arrive avec Gelato que quand tu lances un média, il ne propose pas les pistes disponibles, même en augmentant le probing)
un projet à fork et simplifier un peu, les options user rating et request sont superflues 😀 (mais c’est au delà de mes connaissances actuelles)
Merci de la découverte 🙂
Tu m’en ajoutes encore à ma liste de trucs à tester et partager, elle est déjà longue comme 3 bras 😛
Merci !
Salut, dis moi tes filtres sont où exactement dans aiostreams parce que les miens ne fonctionnent pas du tout… J’ai 30 resultats par films c’est gavant j’ai essayé plein de manières différentes mais rien a faire il ne prends pas mes filtres. Merci d’avance
Salut,
Dans les filtres, déjà dans Deduplicator

Ensuite dans Result limits

ok merci j’ai modifié le manifest et refresh mais toujours pareil, j’ai vraiment l’impression que ca bypass totalement mes filtres